I just thought I would put a post up about Compellent Live Volume.
We now utilise Live Volume for our SQL and we are soon to implement it as part of our Hyper V 3 setup.
I remember when I was researching Live volume and it wasn’t clear exactly what it did and how it worked.
Even when I did the Compellent Admin course it still wasn’t completely clear.
Now I have actually implemented it I can shed some light on the subject.
What does Live Volume do?
It allows a Volume to be hosted on multiple SANs at the same time.
It allows an administrator to designate which SAN the volume is active on – e.g. we need to do maintenance on SAN A so lets make it active on SAN B instead.
It can automatically change which SAN the volume is active on based on the amount on I/O, so the volume is optimally placed.
What does Live Volume not do?
Automated disaster recovery – if you have a SAN failure there is no guarantee the data will be 100% up to date on the replica SAN and the migration to secondary SAN can only be done with the help of Co-Pilot. This is a dodgy game to play as when the failed SAN comes back online it will be out of date but consider itself primary and any changes since Co-Pilot made the other SAN primary could get lost. That is why they don’t let you do this yourself!!!
so what does this look like:
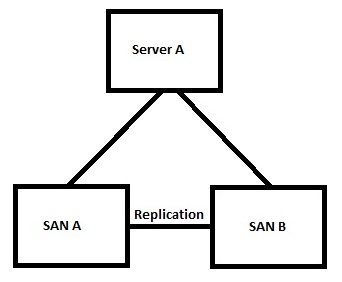
So in this example we have a single server mapped to multiple SANs. In this case this behaves very similarly to a standard replicated volume but with one very helpful difference.
Lets start with the volume being “Live” on SAN A. The volume is mapped and the writes are all sent to SAN A. any changes are replicated across a suitably large replication connection (FC, FCoE or iSCSI). If we need to perform maintenance on SAN A we can make the volume active on SAN B, during this operation the Compellent may actually send some of the operations over the replication link until the path becomes active from Server A to SAN B.
This is really cool as we can now perform all sorts of maintenance on the SAN without scheduling outages for the services provided on Server A.
This may be all some of us want to do but I would wonder who would architect this kind of solution? Normally the servers are cheaper and more likely to fail or need schedule maintenance (patches, firmware etc) and SANs are expensive, more resilient and can be updated online.
I would suspect anyone who can afford two SANs and Live Volume licenses will probably be doing something a little more complicated.
lets look at our old SQL Geo-Cluster:

We have two server and two SANs in a geographically dispersed cluster.
We use EMC Mirrorview to replicate the data.
as part of the cluster we had to add in some software called Mirrorview/CE (Cluster Edition).
this forms a cluster resource and controls on which SAN the volume is active.
this means if we want to fail over from one SAN to another we have to take the cluster resource and associated services offline. The advantage to this in (in theory) if we did have a SAN failure then the cluster would failover and CE would make the other SAN live, I had no way of testing this without pulling the power from the SAN and I guessed I would never find out if it worked.
Unfortunately I was wrong. We had a bit of an incident with a contractor servicing our fire suppression system and we temporarily lost a datacentre. I can say from experience that I had to wait for the SAN to come back up and Mirrorview to get back in sync before the failover would work. I am sure I could have called EMC support and asked them to promote the volume, but there goes my single advantage to the EMC approach. I learned from this episode that Live Volume and CE are similar in the downsides but Live Volume is better in day to day use.
So what does this look like now we utilise Live Volume;
remarkably similar, just replace the words EMC CLARiiON with Compellent.
Whats the difference I hear you ask,
based on a standard MS cluster, not a lot. The SQL instance is active on either Server A or B. We now find the strange situation where we control where the data is processed using Microsoft Clustering and where the data is being accessed using Compellent Enterprise Manager. Although confusing this does allow us to migrate from one SAN to another without doing a cluster failover. Also we can set Live Volume to automatically change the SAN active SAN for each volume based on I/O usage. it’s all good.
Everything so far is based on traditional clustering with a single server accessing a single volume.
that’s not really the case any more as Linux, VMFS or Microsoft CSV allow multiple servers to access the same volume.
so what does this mean to live volume. quite simply it means that theoretically Live Volume is the future for multi site volumes.
We can now have multiple servers in different datacentres accessing the same volume, then based on which servers are using the most I/O the volume will be moved to the optimal SAN.
The I/O is redirected from the passive to the active SAN through the replication link and this is what allows the live volume role swap.
let me build our 8 node multi site Hyper V 3 using Live Volume environment and I will update as to how well it works.